目标检测2 |
您所在的位置:网站首页 › 目标检测 注意力 › 目标检测2 |
目标检测2
|
卷集注意力模块(CBAM)
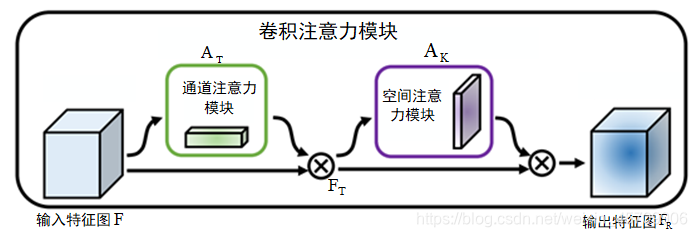
为后续YOLOv4网络加入卷集注意力模块,在这里记录一下卷集注意力模块的理解。 文章目录 卷集注意力模块(CBAM)1.卷集注意力模块整体结构2.通道注意力模块3.空间注意力模块 1.卷集注意力模块整体结构卷积注意力模块是一种结合了通道注意力模块(Channel Attention Module)和空间注意力模块(Spatial Attention Module) 两个维度的注意力机制模块。通过这两个模块分别对输入特征图在 通道向和空间向进行自适应地特征选择和增强,突出主要特征,抑制无关特征,从而使网络更加关注需要检测目标的内容信息和位置 信息,以提高网络的检测精度。 在使用 CBAM 时先输入一个特征图𝐹,其通道数为𝐶,且各个 通道特征图的宽和高均分别为𝑊和𝐻。然后 CBAM 使用通道注意 力模块将输入的特征图 F 转换为一维的通道注意力图 A T A_T AT,再将输入的特征图𝐹与 A T A_T AT进行像素级相乘,得到通道向的显著特征图 F T F_T FT, 计算公式如(1.1)。而后使用空间注意力模块将 F T F_T FT转换为二 维的空间注意力图 A K A_K AK,最后将 F T F_T FT与 A K A_K AK进行像素级相乘得到输出的 特征图 F R F_R FR,计算公式如(1.2)。
F
T
=
A
T
(
F
)
⊗
F
(1.1)
F_T=A_T(F)⊗F \tag{1.1}
FT=AT(F)⊗F(1.1)
F
R
=
A
K
(
F
T
)
⊗
F
T
(1.2)
F_R=A_K(F_T)⊗F_T \tag{1.2}
FR=AK(FT)⊗FT(1.2) 其中⊗代表像素级相乘,以上过程可表示为下图。 在通道注意力模块中,特征图的每一个通道都被认为是一个特征检测器。通道注意力模块关注的是特征在通道间的关系,主要提取输入图像中有意义的内容信息,压缩输入特征图的空间向信息。在CBAM中通道注意力模块同时采用全局平均池化和全局最大池化,其中平均池化反应了全局信息,最大池化反应了特征图中的突出特点,两种不同池化的同时使用可以提取更加丰富的高层次特征。 在通道注意力模块中对输入的特征图F分别进行最大池化和平均池化,生成两个不同的空间信息描述特征图
F
m
a
x
和
F
a
v
g
F_{max}和F_{avg}
Fmax和Favg,再将这两个特征图送入一个共享网络之中计算得到通道注意力图
A
T
A_T
AT。这里的共享网络由含有一个隐藏层的多层感知机(Multilayer Perceptron,MLP)构成。最后通过点像素逐位相加将共享网络输出的两个向量融合为
A
T
A_T
AT,计算方法如公式(2.1)所示。
A
T
=
σ
(
A
v
g
P
o
o
l
(
F
)
)
+
M
L
P
(
M
a
x
P
o
o
l
(
F
)
)
)
=
σ
(
W
1
(
W
0
(
F
a
v
g
)
)
+
W
1
(
W
0
(
F
m
a
x
)
)
)
(2.1)
\begin{aligned} A_T&= \sigma(AvgPool(F))+MLP(MaxPool(F)))\\ & =\sigma(W_1(W_0(F_{avg}))+W_1(W_0(F_{max}))) \end{aligned}\tag{2.1}
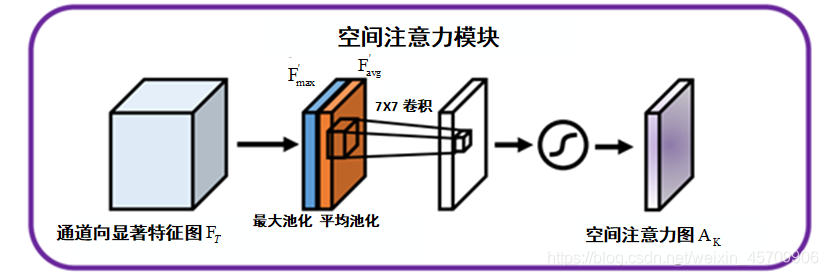
AT=σ(AvgPool(F))+MLP(MaxPool(F)))=σ(W1(W0(Favg))+W1(W0(Fmax)))(2.1) 式中σ表示sigmoid函数,MLP为多层感知机,AvgPool与MaxPool分别表示平均池化与最大池化,
W
1
W_1
W1与
W
0
W_0
W0为多层感知机模型中的参数。以上具体计算过程如下图所示。 空间注意力模块关注的是特征在空间上的关系,主要提取输入图像中目标的位置信息,与通道注意力模块相互补充,选择出特征图中目标的内容和位置信息。在CBAM中空间注意力模块在通道注意力模块之后,将通道向的显著特征图F_T在通道的维度上分别进行最大池化和平均池化,得到两个二维特征图
F
m
a
x
′
F^{'}_{max}
Fmax′和
F
a
v
g
′
F^{'}_{avg}
Favg′,再将得到的两个特征图进行拼接,生成特征描述器,从而突出目标区域,计算方法如公式(3.1)
A
K
=
σ
(
C
o
n
v
7
×
7
(
[
M
a
x
P
o
o
l
(
F
T
)
;
A
v
g
P
o
o
l
(
F
C
)
]
)
)
=
σ
(
C
o
n
v
7
×
7
(
[
F
m
a
x
′
⋅
F
a
v
g
′
]
)
)
(3.1)
\begin{aligned} A_K&= \sigma(Conv_{7\times7}([MaxPool(F_T);AvgPool(F_C)]))\\ & =\sigma(Conv_{7\times7}([F^{'}_{max}\cdot F^{'}_{avg}])) \end{aligned}\tag{3.1}
AK=σ(Conv7×7([MaxPool(FT);AvgPool(FC)]))=σ(Conv7×7([Fmax′⋅Favg′]))(3.1) 最后,使用一个7×7卷积生成二维空间注意力图
A
K
A_K
AK。上述操作步骤可由下图所示。 |


 下面是实现卷积注意力模块的代码,基于Pytorch来写的,后续可以直接植入到YOLOv4网络中使用
下面是实现卷积注意力模块的代码,基于Pytorch来写的,后续可以直接植入到YOLOv4网络中使用【本文地址】
今日新闻 |
推荐新闻 |